This book is short and relatively easy to read, although it took me three years to finish 🫠 (I started it in 2021 but then forgot about it for a while).
The book is packed with examples and practical advice. It introduces some unique concepts that I haven’t encountered in other software architecture books. Beyond specific coding strategies, it also encourages a reassessment of our existing software design mindset, which is way more important.
I have read the first edition of the book, and a second edition has since been released. The author generously provided access to two new chapters from this latest edition. He also mentioned that if you already possess the first edition, it might not be worth buying the second one.
There is also a Google Talk by the author that presents the main points of the book.
Notes
This book is about how to design software systems to minimize their complexity.
The most fundamental problem in computer science is problem decomposition: how to take a complex problem and divide it up into pieces that can be solved independently.
If you can visualize a system, you can probably implement it in a computer program. This means that the greatest limitation in writing software is our ability to understand the systems we are creating.
Complexity will still increase over time, in spite of our best efforts, but simpler designs allow us to build larger and more powerful systems before complexity becomes overwhelming.
There are two general approaches to fighting complexity. The first approach is to eliminate complexity by making code simpler and more obvious. The second approach to complexity is to encapsulate it so that programmers can work on a system without being exposed to all of its complexity at once.
Complexity, defined in a practical way, is anything related to the structure of a software system that makes it hard to understand and modify the system.
Complexity is determined by the activities that are most common. If a system has a few parts that are very complicated, but those parts almost never need to be touched, then they don’t have much impact on the overall complexity of the system. To characterize this in a crude mathematical way:
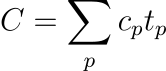
The overall complexity of a system C is determined by the complexity of each part p weighted by the fraction of time developers spend working on that part.
Complexity is more apparent to readers than to writers. If you write a piece of code and it seems simple to you, but other people think it is complex, then it is complex.
Symptoms of complexity: change amplification - when a simple change requires code changes in many different places cognitive load - when a developer needs to know a lot in order to complete a task unknown unknowns - when it is not obvious which pieces of code must be modified to complete a task or what information the developer must have to carry out the task successfully (out of all symptoms, this is the worst)
People sometimes assume that complexity can be measured by lines of code. They assume that if one implementation is shorter than another, then it must be simpler; if it only takes a few lines of code to make a change, then the change must be easy. However, this view ignores the costs associated with cognitive load. Sometimes, an approach that requires more lines of code is actually simpler because it reduces cognitive load.
Complexity is caused by two things: dependencies and obscurity.
A dependency exists when a given piece of code cannot be understood and modified in isolation; the code relates in some way to another code, and the other code must be considered and/or modified.
Obscurity occurs when important information is not obvious.
Obscurity is often associated with dependencies, where it is not obvious that a dependency exists.
Dependencies lead to change amplification and a high cognitive load. Obscurity creates unknown unknowns, and also contributes to cognitive load.
Complexity isn’t caused by a single catastrophic error; it accumulates in lots of small chunks.
The incremental nature of complexity makes it hard to control. It’s easy to convince yourself that a little bit of complexity introduced by your current change is not a big deal. However, if every developer takes this approach for every change, complexity accumulates rapidly. Once complexity has accumulated, it is hard to eliminate, since fixing a single dependency or obscurity will not, by itself, make a big difference.
Most programmers approach software development with a tactical programming mindset. In this tactical approach, your main focus is to get something working, such as a new feature or bug fix.
The problem with tactical programming is that it is short-sighted, and planning for the future is not a priority. You don’t spend much time looking for the best design; you just want to get something working soon. You tell yourself that it’s ok to add a bit of complexity or introduce a small kludge or two, if that allows the current task to be completed more quickly.
Most of the code in any system is written by extending the existing codebase, so your most important job as a developer is to facilitate those future extensions. Thus, you should not think of “working code” as your primary goal, though, of course, code must work. Your primary goal must be to produce a great design, which also happens to work. This is strategic programming.
Strategic programming requires an investment mindset. Rather than taking the fastest path to finish the current project, you must invest time to improve the design of the system.
A huge up-front investment, such as trying to design the entire system, won’t be effective. This is the waterfall method, and we know it doesn’t work. The ideal design tends to emerge in bits and pieces, as you get experience with the system. Thus, the best approach is to make lots of small investments on a continual basis, adding up to about 10-20% of your total development time.
One of the most important techniques for managing software complexity is to design systems so that developers only need to face a small fraction of the overall complexity at any given time. This approach is called modular design.
The goal of modular design is to minimize dependencies between modules.
In order to manage dependencies, we think of each module in two parts: an interface and an implementation. The interface consists of everything that a developer working in a different module must know in order to use the given module. Typically, the interface describes what that module does but not how it does it. The implementation consists of the code that carries out the promises made by the interface. A developer working in a particular module must understand the interface and implementation of that module, plus the interfaces of any other modules invoked by the given module. A developer should not need to understand the implementation of modules other than the one they are working on.
A module is any unit of code that has an interface and implementation. Each class in an object-oriented programming language is a module. Methods within a class, or functions in a language that is not object-oriented, can also be thought of as modules: each of these has an interface and an implementation, and modular design techniques can be applied to them.
The best modules are those whose interfaces are much simpler than their implementations.
The interface to a module contains two kinds of information: formal and informal.
The formal parts of an interface are explicitly specified in the code, and some of these can be checked for correctness by the programming language. For example, the formal interface for a method is its signature. The formal interface for a class consists of the signatures for all of its public methods plus the names and types of any public variables.
Each interface also includes informal elements. These are not specified in a way that can be understood or enforced by the programming language. The informal parts of an interface include its high-level behavior, such as the fact that a function deletes the file named by one of its arguments. If there are constraints on the usage of a class (perhaps one method must be called before another), these are also parts of the class’ interface.
In general, if a developer needs to know a particular piece of information in order to use a module, then that information is part of the module’s interface.
The informal aspects of an interface can only be described using comments, and the programming language can not ensure that the description is complete or accurate. For most interfaces, the informal aspects are larger and more complicated than the formal aspects.
The term abstraction is closely related to the idea of modular design. An abstraction is a simplified view of an entity, which omits unimportant details. In modular design, each module provides an abstraction in the form of its interface. The interface presents a simplified view of the module’s functionality; the details of the implementation are unimportant from the standpoint of the module’s abstraction, so they are omitted from the interface.
The best modules are deep: they allow a lot of functionality to be accessed through a simple interface. A shallow module is one with a relatively complex interface, but not much functionality; it doesn’t hide much complexity.
The most important issue in designing classes and other modules is to make them deep, so that they have simple interfaces for the common use cases, yet still provide significant functionality. This maximizes the amount of complexity that is concealed.
Students are often taught that the most important thing in class design is to break up larger classes into smaller ones. The same advice is often given about methods: “Any method longer than N lines should be divided into multiple methods”. This approach results in large numbers of shallow classes and methods, which add to overall system complexity.
The most important technique for achieving deep modules is information hiding. The basic idea is that each module should encapsulate a few pieces of knowledge, which represent design decisions. The knowledge is embedded in the module’s implementation but does not appear in its interface, so it is not visible to other modules.
Information hiding can often be improved by making a class slightly larger.
The opposite of information hiding is information leakage. Information leakage occurs when a design decision is reflected in multiple modules.
When designing modules, focus on the knowledge that’s needed to perform each task, not the order in which tasks occur.
If the API for a commonly used feature forces users to learn about other features that are rarely used, this increases the cognitive load on the users who don’t need the rarely used features.
General-purpose interfaces have many advantages over special-purpose ones. They tend to be simpler, with fewer methods that are deeper. They also provide a cleaner separation between classes, whereas special-purpose interfaces tend to leak information between classes. Making your modules somewhat general-purpose is one of the best ways to reduce overall system complexity.
Each piece of design infrastructure added to a system, such as an interface, argument, function, class, or definition, adds complexity, since developers must learn about this element. In order for an element to provide a net gain against complexity, it must eliminate some complexity that would be present in the absence of the design element.
The “different layer, different abstraction” rule is just an application of this idea: if different layers have the same abstraction, such as pass-through methods or decorators, then there’s a good chance that they haven’t provided enough benefit to compensate for the additional infrastructure they represent.
Most modules have more users than developers, so it is better for the developers to suffer than the users. As a module developer, you should strive to make life as easy as possible for the users of your module, even if this means extra work for you. Another way of expressing this idea is that it is more important for a module to have a simple interface than a simple implementation.
When developing a module, look for opportunities to take a little bit of extra suffering upon yourself in order to reduce the suffering of your users.
Length by itself is rarely a good reason for splitting up a method. In general, developers tend to break up methods too much. Splitting up a method introduces additional interfaces, which add to complexity. It also separates the pieces of the original method, which makes the code harder to read if the pieces are actually related. You shouldn’t break a method unless it makes the overall system simpler.
When designing methods, the most important goal is to provide clean and simple abstractions. Each method should do one thing and do it completely.
The decision to split or join modules should be based on complexity. Pick the structure that results in the best information hiding, the fewest dependencies, and the deepest interfaces.
Programmers exacerbate the problems related to exception handling by defining unnecessary exceptions. Most programmers are taught that it is important to detect and report errors; they often interpret this to mean “the more errors detected, the better”.
The exceptions thrown by a class are part of its interface; classes with lots of exceptions have complex interfaces, and they are shallower than classes with fewer exceptions.
Throwing exceptions is easy, but handling them is hard. Thus, the complexity of exceptions comes from the exception handling code. The best way to reduce the complexity damage caused by exception handling is to reduce the number of places where exceptions have to be handled.
The best way to eliminate exception handling complexity is to define your APIs so that there are no exceptions to handle: define errors out of existence.
The design-it-twice approach not only improves your design, but also your design skills. The process of devising and comparing multiple approaches will teach you about the factors that make designs better or worse. Over time, this will make it easier for you to rule out bad designs and hone in on really great ones.
In-code documentation plays a crucial role in software design. Comments are essential to help developers understand a system and work efficiently, but the role of comments goes beyond this. Documentation also plays an important role in abstraction; without comments, you can’t hide complexity. Finally, the process of writing comments, if done correctly, will actually improve a system’s design.
When developers don’t write comments, they usually justify their behavior with one or more of the following excuses:
- “Good code is self-documenting.”
- “I don’t have time to write comments.”
- “Comments get out of date and become misleading.”
- “The comments I have seen are all worthless; why bother?”
Some developers argue that if others want to know what a method does, they should just read the code of the method: this will be more accurate than any comment. It’s possible that a reader could deduce the abstract interface of the method by reading its code, but it would be time-consuming and painful.
If you write code with the expectation that users will read method implementations, you will try to make each method as short as possible, so that it’s easy to read.
If users must read the code of a method in order to use it, then there is no abstraction: all the complexity of the method is exposed.
The overall idea behind comments is to capture information that was in the mind of the designer but couldn’t be represented in the code.
The idea of an abstraction is to provide a simple way of thinking about something, but the code is so detailed that it can be hard to see the abstraction just from reading it.
Even if this information can be deduced by reading the code, we don’t want to force users of a module to do that: reading the code is time-consuming and forces them to consider a lot of information that isn’t needed to use the module.
Developers should be able to understand an abstraction provided by a module without reading any code other than its externally visible declarations.
A first step towards writing good comments is to use different words in the comment from those in the name of the entity being described.
Comments augment the code by providing information at a different level of detail.
Some comments provide information at a lower, more detailed level than the code: these comments add precision by clarifying the exact meaning of the code. Other comments provide information at a higher, more abstract level than the code: these comments offer intuition, such as reasoning behind the code, or a simpler and more abstract way of thinking about the code. Comments at the same level as the code are likely to repeat the code.
When documenting a variable, think nouns, not verbs. In other words, focus on what the variable represents, not how it is manipulated.
The first step in documenting abstractions is to separate interface comments from implementation comments. Interface comments provide information that someone needs to know in order to use a class or a method; they define the abstraction. Implementation comments describe how a class or method works internally in order to implement the abstraction. It’s important to separate these two kinds of comments so that users of an interface are not exposed to implementation details.
The main goal of implementation comments is to help readers understand what the code is doing (not how it does it).
The goal of comments is to ensure that the structure and behavior of the system are obvious to the readers, so they can quickly find the information they need and make modifications to the system with confidence that they will work.
When following the rule that comments should describe things that are not obvious from the code, “obvious” is from the perspective of someone reading your code for the first time (not you). When writing comments, try to put yourself in the mindset of the reader and ask yourself what are the key things they will need to know.
A good name conveys a lot of information about what the underlying entity is and, just as important, what it is not.
Unfortunately, when developers get into existing code to make changes such as bug fixes or new features, they don’t think strategically. A typical mindset is “what is the smallest possible change I can make that does what I need”. Sometimes, developers justify this because they are not comfortable with the code being modified; they worry that larger changes carry a greater risk of introducing new bugs.
Ideally, when you have finished with each change, the system will have the structure it would have had if you had designed it from the start with that change in mind.
Every development organization should plan to spend a small fraction of its total effort on cleanup and refactoring; this work will pay for itself over the long run.
When writing implementation comments, don’t put all the comments for an entire method at the top of that method. Spread them out, pushing each comment down to the narrowest scope that includes all of the code referred to by the comment.
In general, the farther a comment is from the code it describes, the more abstract it should be (this reduces the likelihood that the comment will be invalidated by code changes).
When writing a commit message, ask yourself whether developers will need to use that information in the future. If so, then document this information in the code.
Comments are easier to maintain if they are higher-level and more abstract than the code.
Developing incrementally is generally a good idea, but the increments of development should be abstractions, not features. It’s fine to put off all thoughts about a particular abstraction until it’s needed by a feature.
The problem with test-driven development is that it focuses attention on getting specific features working rather than finding the best design.
One place where it makes sense to write the tests first is when fixing bugs. Before fixing a bug, write a unit test that fails because of the bug.
The greatest risk with design patterns is over-application. Not every problem can be resolved cleanly with an existing design pattern; don’t try to force a problem into a design pattern when a custom approach will be cleaner.
It’s tempting to rush off and start making performance tweaks based on your intuition about what is slow. Don’t do this! Programmers’ intuition about performance is unreliable. Before making any changes, measure the system’s existing behavior.
The reward for being a good designer is that you get to spend a larger fraction of your time in the design phase, which is fun. Poor designers spend most of their time chasing bugs in complicated and brittle code. If you improve your design skills, not only will you produce higher quality software more quickly, but the software development process will be more enjoyable.